kubernetes의 기초
kebernates 개념 알아보기
쿠버네티스가 뭐야?
쿠버네티스 는 container 오케이스트레이션 플랫폼으로 현재는 사실상 표준처럼 사용된다. 여러대의 서버가 존재하는 클러스터에서 container 관리를 위해 사용된다.
공식 홈페이지 에 따르면
“쿠버네티스는 container화된 워크로드와 서비스를 관리하기 위한 이식성이 있고, 확장가능한 오픈소스 플랫폼이다” 라고 설명하고 있다.
쿠버네티스가 왜 필요했을까?
 출처 https://kubernetes.io/ko/docs/concepts/overview/what-is-kubernetes/
출처 https://kubernetes.io/ko/docs/concepts/overview/what-is-kubernetes/
초기에는 하나의 물리적 서버에 모든 application을 실행했다. 상식적으로,, application이 아무리 가볍다해도 혼자 쓰는 TODO List 같은게 아닌 이상 이는 감당이 안된다.
이때문에 등장한 것이 가상화 였다. 하나의 호스트에 VM을 여러개 띄어서 application을 격리 시킨것이다. 이 때 VM은 하나의 OS자체를 가상화시켰다.
os 자체를 가상화 시키고 있기때문에,, 굉장히 무겁다. 때문에 등장한 것이 container 개념이다. Host의 OS를 공유한다.
그리고 이 container를 관리하기 위해 쿠버네티스가 등장했다.
쿠버네티스의 주요 개념
1. Object
가장 기본적인 구성단위로 Ojbect는 쿠버네티스의 상태를 나타내는 엔티티이다. Ojbect는 Spec과 Status를 가지고 있다.
Pod, Service, Volume, Namespace 4가지가 존재한다.
- Pod: 컨테이너화된 어플리케이션
- Service: load balancer, 과도한 트래픽이 발생하는 상황에서 여러 대의 서버가 분산처리하여 이를 해결하는 서비스
Service는 label selector를 가진다. 이는 Pod에서 Metadata에 Label을 설정해줄 수 있는데, 특정 Label을 가진 Pod만 선택하여 Service할 수 있다.- Label은 리소스 선택 시 사용된다. 특정 리소스 배포 또는 service에 해당 label을 부여할 수 있다.
"metadata":{ "label_k":"data", "label_k_n":"data_n" }
- Label은 리소스 선택 시 사용된다. 특정 리소스 배포 또는 service에 해당 label을 부여할 수 있다.
- Volume: Disk, 영속적으로 저장되어야 하는 데이터의 경우 볼륨을 마운트해서 이용해야한다.
- Namespace: pakage name, 클러스터 내의 논리적 분리 단위(물리적 분리가 아님!!) 로 네임스페이스별로 리소스를 나눠 관리할 수 있고, 사용자의 권한을 다르게 할 수도 있다.
2. Controller
Object의 Status를 사용자가 원하는 형태(Desired State)로 Current State를 변경시켜주는 주체
Desired State★★ 완전 중요 ★★
쿠버네티스는 Desired State가 중요하다. 이는 application의 최종 배포 상태를 의미한다. 사용자가 원하는 state를 알려주면 쿠버네티스는 작업을 통해 state를 변경한다.쿠버네티스 나를 고급개발자로 설정해줘
이 때, controller 에 의해 state가 변경되는데, control-loop를 기반으로 리소스 모니터링을 진행한다. control-loop는Observe -> check Differeneces -> Take Action의 순서로 loop를 돈다.
그럼 여기서 말하는 state가 뭘까? 내가 원하는 웹서버, 포트, 리소스 등을 의미한다. 설정하는 방법은 YAML이나 JSON을 이용할 수 있다. 해당 파일에 application의 상태를 명시하면 이를 쿠버네티스가 보고 알아서 해준다는 것! 우와~😚
쿠버네티스 공식 페이지 설명 에서 아래 종류에 관해 자세하게 확인이 가능하다.
- Replication Controller: Pod 관리, Pod가 너무 많으면 제거하고 너무 적으면 Pod를 시작한다.
- Replicaset: Replica Pod set의 실행을 항상 안정적으로 유지해줌 Replication Controller와 비슷하게 Pod을 관리하는데, controller는 Equality기반 Selector를 사용하는 반면 Replicaset은 Set기반 Selector를 사용한다.
- equality는 a=b, set기반은 a in (prod, dev) 와 같이 selection 방법이 다르다.
- DaemonSet: Node가 Pod의 사본을 실행하도록 함, 클러스터 스토리지 데몬 실행, 로그 수집 데몬 실행, 노드 모니터링 데몬 실행이 대표적인 용도임
- Job: Job에서 하나 이상 Pod를 생성하고 지정 수의 Pod가 성공적으로 종료될 때까지 지속해서 관리
- StatefulSet: 말 그대로 어플리케이션의 Stateful을 관리하는데 사용되는 API
- Deployment: Pod와 Replicaset에 대한 선언적 업데이트 제공
- Blue Green Deployment: Blue(old version) —(traffic)-> Green(new version)
- 롤링 업그레이드: Pod를 하나씩 옮김
3. Pod
이다. 쿠버네티스는 이 Pod을 효율적으로 사용하여 Controller를 통해 state manazement를 진행한다. 즉, Pod의 life cycle을 쿠버네티스가 관리한다.
- 쿠버네티스는 컨테이너를 Pod 단위로 배포한다.
- 1개의 Pod은 여러개의 container를 가질 수 있다. Pod은 이 내부 container와 id, port, volumne 등을 공유하고 localhost 통신도 가능하다.
- pause라는 container가 먼저 실행되고 이 contatiner의 namespace를 pod 내의 container가 공유하는 것이다.
- Pod 단위로 스케일링이 진행된다.
- 1개의 Pod은 1개의 Node위에서 실행됨
- ReplicaSet Controller에 의해 복제 생성될 수 있다.
Pod 생성을 요청하면 아래 과정대로 흐름이 진행된다.
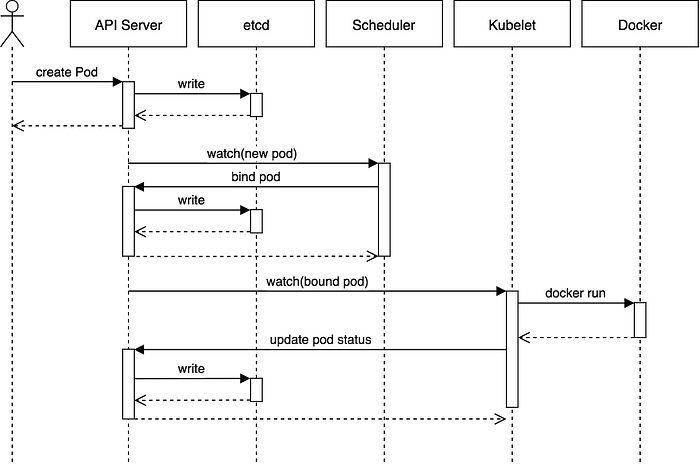
출처 https://blog.heptio.com/core-kubernetes-jazz-improv-over-orchestration-a7903ea92ca
쿠버네티스는 어떻게 생겼을까?
공식홈페이지에서 제공하는 쿠버네티스의 구조는 아래와 같다. control(master) - node(worker:container 배포) 형태이다.
master에는 다양한 컴포넌트가 존재한다.
 출처 https://kubernetes.io/ko/docs/concepts/overview/components/
출처 https://kubernetes.io/ko/docs/concepts/overview/components/
Master
-
kube-apiserver 쿠버네티스의 api를 다른 component에게 응답하기 위해 사용한다. 그러므로 cluster는 이 api server가 중심이 되어 통신이 되는 것이다.
-
etcd 모든 cluster의 data를 저장한다. key-value database다.
-
kube-schduler 노드들을 모니터링해서 새로운 pod를 생성한다.
-
kube-controller-manager pod 관리 컨트롤러
-
colud-contoller-manager 모든 쿠버네티스의 컨트롤러를 cloud service와 연결해서 managing.
Worker
-
kubelet(node manager) cluster의 각 node에서 실행되는
핵심 컴포넌트제공된 Spec을 통해 container를 실행시킨다. 또한, 지속적인 모니터링과 master node와 api server 통신을한다. -
kube-proxy(network proxy) 쿠버네티스의 service object를 구현한다. node의 network 규칙을 관리한다.
-
container runtime
실제로 container를 실행하는 소프트웨어
쿠버네티스로 정확히 뭘 할 수 있는걸까!?
- 자동화된 rolllout rollback
- 자동화된 bin packing: container화된 작업을 실행하는데 사용 할 수 있는 kube-cluser node를 제공한다.
- 자동화된 self-healing: 실패한 컨테이너를 다시 시작한다.
등.. 자세한 내용은 https://kubernetes.io/ko/docs/concepts/overview/what-is-kubernetes/ 에서 추가로 확인할 수 있다.
쿠버네티스 뭐가 좋고 나쁠까?
왜 쿠버네티스가 사실상 표준이라고 할 정도로 좋은걸까?이 글 에서 기획자/ 운영자/ 개발자 측면에서 자세하게 정리해주셨다. 전체적으로 봤을 땐 확장성, 자동화, 속도, 비용 효율적인 면이 큰 것같다.
반대로 이 글 에서는 쿠버네티스의 단점에 대해서도 이야기하고 있다. 일단은 런닝커브가 매우 크다는 점이다. (나 또한 절실히 느끼고 있다…ㅠㅠ) 두번째로는 소규모 플젝에서는 쿠버네티스가 그닥 유용하지 않을 수도 있다는 것이다(불필요한 복잡성)
REFERENCES
https://nesoy.github.io/articles/2018-06/Load-Balancer
https://theoriginalcatch.com/27
https://blog.2dal.com/2018/03/28/kubernetes-01-pod/
https://kubernetes.io/ko/docs/concepts/overview/components/
https://tech.ktcloud.com/68
https://subicura.com/쿠버네티스/guide/#minikube
https://velog.io/@gentledev10/install-minikube